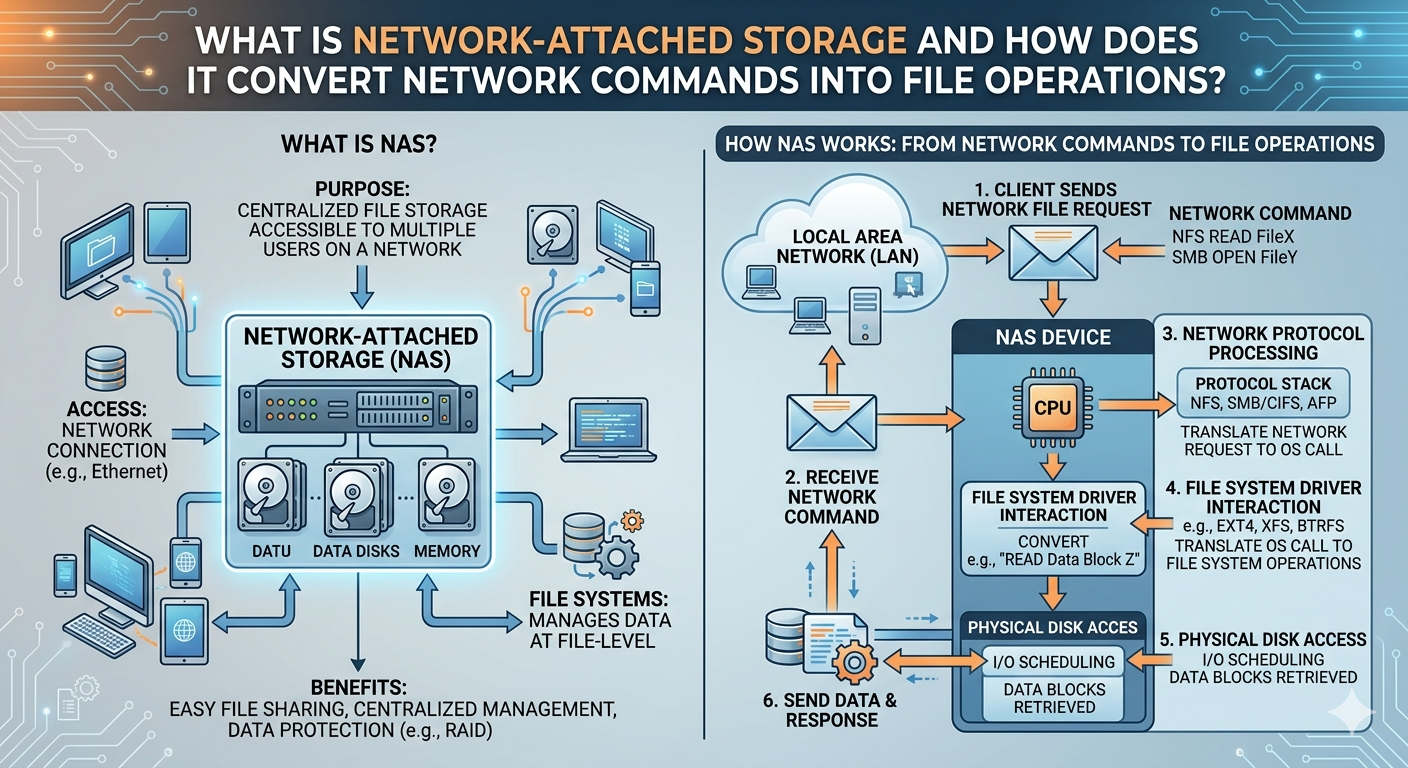
Organizations require robust mechanisms for managing unstructured data across distributed environments. Centralized data repositories solve critical access and latency issues across wide and local area networks. When enterprise administrators evaluate storage architecture, a foundational question often arises: what is network attached storage? Fundamentally, it is a dedicated file-level storage architecture that enables multiple users and heterogeneous client devices to retrieve data from a centralized pool of disk capacity.
By operating as an independent node on a network, this architecture decouples data access from general-purpose application servers. This separation reduces the processing load on application servers and optimizes file sharing across the enterprise. Understanding what is network attached storage requires examining its core hardware components, its specialized operating systems, and its reliance on standardized network protocols to facilitate seamless data retrieval.
This article outlines the technical mechanisms behind these systems. It details exactly how incoming network commands translate into physical file operations on a disk. Furthermore, it explains how deploying Scale out nas Storage environments supports enterprise growth by mitigating the performance bottlenecks found in legacy storage architectures.
The Architecture of Dedicated File Storage
To fully grasp what is network attached storage, IT professionals must look at its internal architecture. Unlike a standard server running a multifaceted operating system, a dedicated storage appliance utilizes a highly stripped-down, optimized operating system. This operating system focuses exclusively on routing, storing, and serving files.
Core Hardware Components
The physical appliance contains standard computing components, including a central processing unit (CPU), random access memory (RAM), and network interface cards (NICs). However, these components are specifically tuned for high-throughput input/output (I/O) operations rather than compute-intensive tasks. The chassis houses multiple storage drives, which can be hard disk drives (HDDs), solid-state drives (SSDs), or non-volatile memory express (NVMe) modules. These drives are typically configured in a Redundant Array of Independent Disks (RAID) to provide fault tolerance and maintain data integrity in the event of a hardware failure.
Software and Protocol Support
The operating system coordinates the file system layer and the network layer. It supports standardized file-sharing protocols, most notably the Network File System (NFS) for Unix and Linux environments, and the Server Message Block (SMB) protocol for Windows environments. By supporting these application-layer protocols simultaneously, the system acts as a universal translator, allowing entirely different client operating systems to access the exact same centralized data repository without formatting conflicts.
Converting Network Commands into File Operations
The primary technical function of this architecture is translating high-level network requests into low-level mechanical or electrical disk operations. When a user or application requests a file, a complex but highly optimized sequence of events occurs in milliseconds.
The Role of Network Protocols
The process begins when a client machine initiates a request over the Local Area Network (LAN) using TCP/IP. The client's operating system generates a file request (such as OPEN, READ, or WRITE) and formats it according to the appropriate protocol, such as SMB or NFS. This request is encapsulated into TCP segments, packaged into IP packets, and finally framed into Ethernet frames for physical transmission across the network cabling.
Packet Decapsulation and Translation
Upon reaching the network interface card of the storage appliance, the hardware strips away the Ethernet and IP headers. The appliance's operating system processes the TCP segment to ensure data integrity and reassembles the payload. The payload contains the original SMB or NFS command.
At this stage, the Virtual File System (VFS) layer intercepts the command. The VFS acts as an abstraction layer, translating the network-specific file command into a standard POSIX-compliant file operation. The VFS determines exactly where the requested file logically resides within its directory structure.
Block-Level Execution
Once the logical location is identified, the local file system translates the request into block-level instructions. It calculates exactly which physical sectors or flash memory blocks hold the requested data. The system's storage controller then executes Small Computer System Interface (SCSI) or NVMe commands to physically read the data from or write the data to the drives. The data is pulled into the system's RAM, repackaged into SMB or NFS responses, encapsulated back into TCP/IP packets, and transmitted back to the client.
Expanding Capacity with Scale Out NAS Storage
As enterprise data volumes grow exponentially, traditional storage architectures often hit hard performance ceilings. In a traditional "scale-up" configuration, administrators add more disk enclosures to a single storage controller. Eventually, the CPU and RAM of that single controller become saturated, leading to severe latency. To solve this, enterprises utilize Scale out nas Storage.
Distributed File Systems
Scale out nas Storage fundamentally changes the expansion model. Instead of adding passive disk shelves to a single monolithic controller, administrators add entire nodes to a cluster. Each node contains its own CPU, memory, networking capabilities, and storage capacity.
A distributed file system ties these independent nodes together, presenting them to the client network as a single, unified namespace. When an organization questions what is network attached storage in a modern enterprise context, the answer almost always involves this clustered approach.
Linear Performance Scaling
The primary technical advantage of Scale out nas Storage is linear scaling. Because each new node brings additional computing power and network bandwidth alongside storage capacity, the overall performance of the cluster increases with every expansion. If an organization experiences a surge in concurrent user connections, Scale out nas Storage automatically balances the incoming network load across all available nodes in the cluster.
This architecture prevents any single node from becoming a bottleneck. Data is striped or mirrored across multiple nodes, ensuring high availability. If one node experiences a hardware failure, the distributed file system automatically reroutes client requests to surviving nodes, ensuring continuous data access without administrative intervention.
Optimizing Enterprise Data Management
Implementing a robust data storage architecture requires careful planning and a deep understanding of network traffic patterns. Administrators must accurately provision network bandwidth, select appropriate RAID levels, and configure file-sharing protocols to ensure security and performance.
By clearly defining what is network attached storage, organizations can move beyond basic file sharing to build resilient, high-performance data pipelines. The continuous translation of high-level network commands into precise block-level disk operations ensures that users experience local-disk performance across wide networks. Furthermore, by transitioning to Scale out nas Storage, IT departments can guarantee that their storage infrastructure will adapt dynamically to future capacity and throughput demands, securing the enterprise's most valuable digital assets.