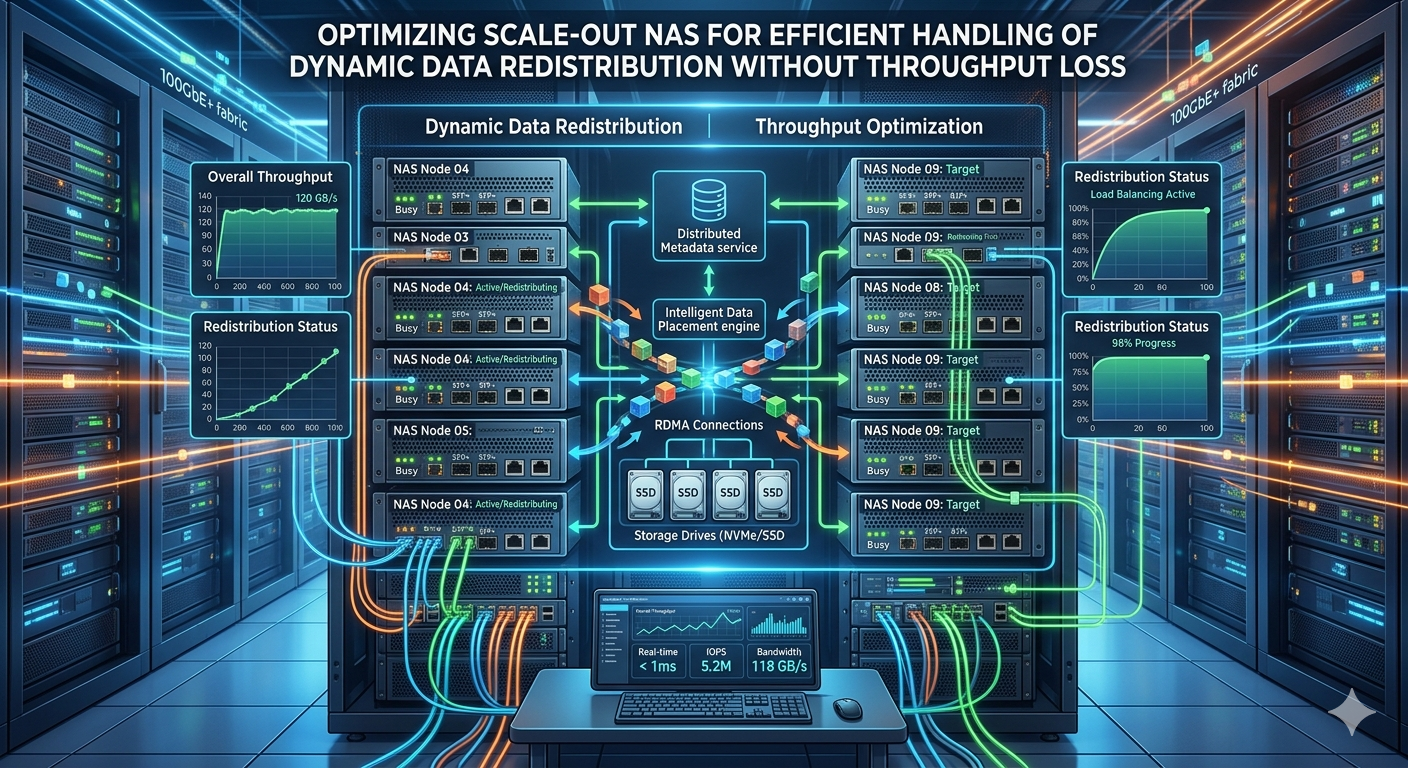
As enterprise storage environments grow, managing capacity and performance requires sophisticated architectures. A primary challenge arises when nodes are added or removed from a storage cluster. This triggers dynamic data redistribution. Left unoptimized, this process can severely degrade client throughput and increase overall latency.
Administrators must implement mechanisms to balance these internal operations with external client workloads. A well-architected Nas System utilizes intelligent algorithms to handle node rebalancing gracefully. Achieving this balance ensures high availability and consistent performance across the entire storage infrastructure.
This article examines the technical strategies required to optimize a Scale out nas during data redistribution. It details workload management, network considerations, and the critical importance of integrating a reliable NAS Backup strategy to protect data during these intensive background operations.
The Mechanics of Data Redistribution
When expanding a Scale out nas, the cluster must move blocks or files to the newly added nodes. This prevents hot spots and maximizes overall cluster utilization. The Nas System must identify which data sets are cold or less frequently accessed, moving them first to minimize disruption to active client connections.
Dynamic data redistribution consumes significant network bandwidth, central processing unit (CPU) cycles, and disk input/output (I/O). If the storage controller does not throttle these background tasks, front-end throughput plummets. Advanced systems use quality of service (QoS) policies to prioritize client reads and writes over internal rebalancing tasks.
Workload Throttling and Quality of Service
Implementing granular QoS is essential for maintaining predictable performance. The Scale out nas should dynamically adjust the resources allocated to data movement based on real-time client load. During peak business hours, the system restricts internal transfer speeds to reserve bandwidth for critical applications. When client I/O drops during off-peak hours, the cluster accelerates the redistribution process. This dynamic scaling ensures that background operations complete efficiently without starving production workloads of essential resources.
Architectural Strategies for a Resilient Nas System
Designing a robust storage environment requires a deep understanding of network topology and node interconnects. A modern Nas System separates client traffic from internal cluster communication. By utilizing dedicated back-end networks—often leveraging high-speed Ethernet or InfiniBand—nodes can transfer data among themselves without competing with client requests.
Metadata Management
Efficient metadata handling drastically reduces the overhead associated with moving data. A distributed metadata architecture allows every node in the Scale out nas to participate in namespace management. This prevents any single node from becoming a bottleneck during the redistribution phase. When a file moves to a new physical location, the metadata updates instantly across the cluster, ensuring seamless client access without requiring a complete directory rescan.
Network Optimization Techniques
Jumbo frames, link aggregation, and Remote Direct Memory Access (RDMA) provide substantial performance improvements during cluster rebalancing. RDMA enables memory-to-memory data transfers between storage nodes, bypassing the CPU entirely. This allows the Nas System to redistribute petabytes of data with minimal latency and near-zero impact on the compute resources needed for standard operations. Implementing these network protocols correctly is a critical step in isolating internal workloads from external throughput demands.
Integrating and Securing Data with NAS Backup
Data mobility introduces inherent risks. While modern file systems use erasure coding and mirroring to protect data internally, these mechanisms do not replace a dedicated NAS Backup. During extensive rebalancing, a hardware failure or power loss could potentially interrupt the file transfer process, leading to logical corruption.
Establishing a comprehensive NAS Backup protocol ensures that a pristine copy of the data exists outside the active cluster. Administrators should schedule incremental backups prior to initiating large-scale node additions to secure critical assets against unforeseen hardware failures.
Snapshot Integration
Many organizations use redirect-on-write snapshots to secure data instantly. Integrating these local snapshots with a robust NAS Backup workflow provides a fail-safe recovery point. If an error occurs during data redistribution, the storage team can revert to the snapshot or pull the required files directly from the NAS Backup repository, minimizing downtime and data loss.
Offsite Replication
For disaster recovery, replicating the NAS Backup to an offsite location or a cloud repository provides maximum security. The Scale out nas can utilize asynchronous replication protocols to transmit compressed, deduplicated data to a secondary site. This ensures business continuity even if the primary data center experiences a catastrophic failure during a cluster expansion phase.
Maintaining Continuous Throughput
To sustain high throughput, storage architects must configure client access protocols intelligently. Utilizing SMB Multichannel or NFSv4.1 multipathing allows clients to establish multiple connections across different network interfaces. If the Nas System momentarily pauses a connection to finalize a file move, the client transparently shifts traffic to an alternate path without dropping the application session.
Furthermore, intelligent client load balancing directs new connection requests to nodes with the lowest CPU and memory utilization. This prevents clients from overwhelming nodes that are actively participating in heavy data redistribution. The combination of multipathing and load balancing ensures that the Scale out nas delivers consistent, predictable performance under all operating conditions.
Frequently Asked Questions
How does a Scale out nas differ from a scale-up architecture?
A Scale out nas adds both storage capacity and compute performance simultaneously by adding independent nodes to a cluster. In contrast, scale-up storage relies on a single controller pair, where adding disk shelves increases capacity but not necessarily compute power. The scale-out approach inherently requires efficient data redistribution to utilize new nodes effectively.
Why is a dedicated NAS Backup necessary if the cluster uses erasure coding?
Erasure coding protects against drive or node failures by distributing parity data across the Nas System. However, it does not protect against accidental file deletions, malicious ransomware attacks, or logical file system corruption. A dedicated NAS Backup provides an isolated, point-in-time copy of the data for comprehensive disaster recovery.
Can redistribution occur without impacting active client I/O?
Yes, provided the Nas System is configured with robust QoS policies, dedicated back-end networks for internode communication, and dynamic CPU throttling. These features allow the cluster to prioritize active client reads and writes while managing background data movement during periods of lower utilization.
Strategic Next Steps for Storage Administrators
Optimizing storage infrastructure requires continuous monitoring and proactive management. Organizations utilizing a Scale out nas must regularly review their network topologies, QoS configurations, and data protection strategies. Implementing dedicated back-end networks and dynamic throttling mechanisms will safeguard client throughput during internal operations.
Ensure that your architecture includes a resilient, verified NAS Backup process to mitigate the risks associated with large-scale data mobility. By systematically applying these technical principles, storage administrators can scale their environments seamlessly, supporting enterprise data growth without sacrificing performance or data integrity.