Managing vast amounts of unstructured data requires storage architectures that can expand without disrupting existing workflows. Legacy storage environments often force administrators into exhaustive manual data migration when adding capacity. This process introduces downtime, risk, and severe administrative overhead. A modern scale out nas resolves this bottleneck by implementing automated, algorithm-driven mechanisms. By utilizing hash-based data distribution, these advanced networks intelligently place data across multiple nodes, entirely eliminating the need for manual rebalancing as the cluster grows. This post explains the technical mechanics behind this approach and how it optimizes enterprise storage infrastructure.
The Limitations of a Traditional NAS System
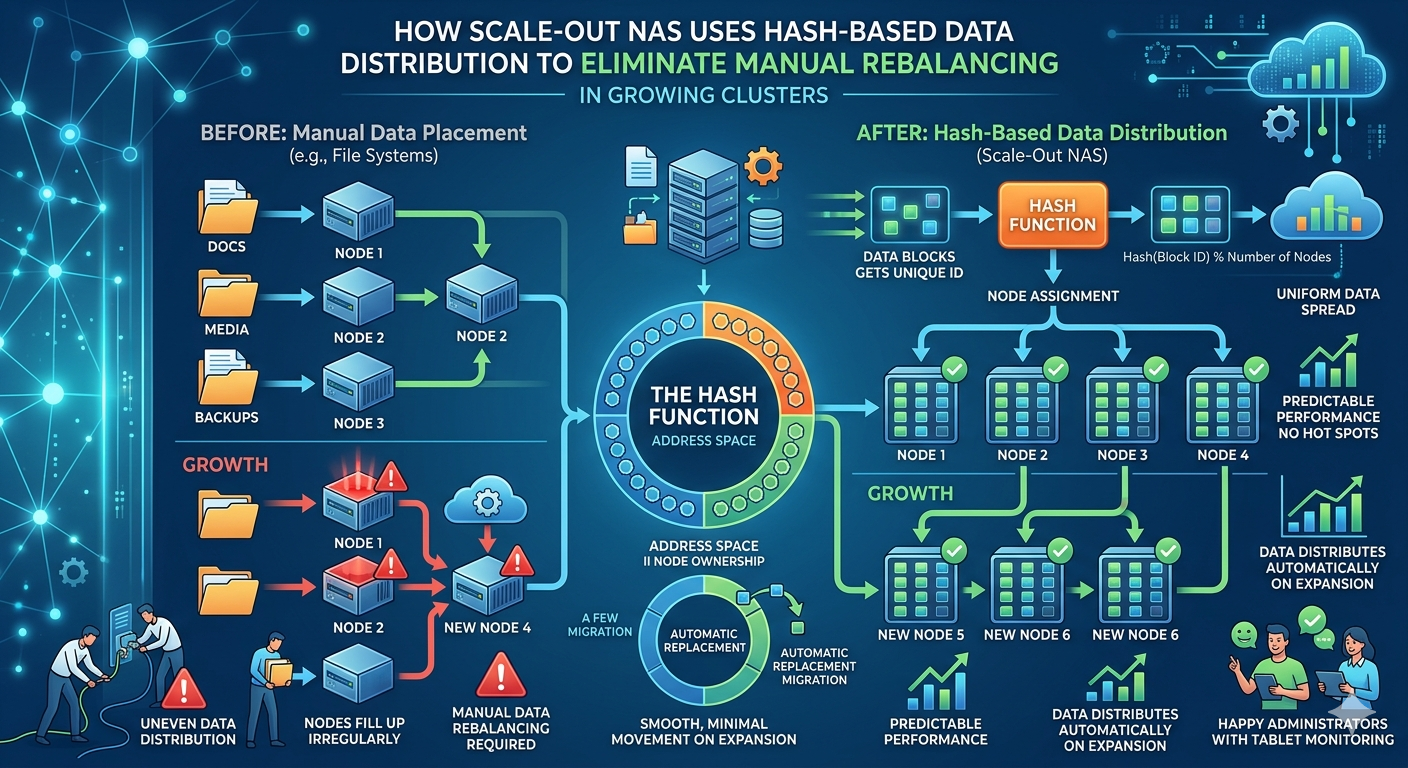
A conventional nas system relies on a scale-up architecture consisting of dual controllers and attached disk shelves. When controllers reach their performance limits or disk shelves reach maximum capacity, administrators must undergo forklift upgrades or deploy a completely separate nas system to handle new workloads. Each new appliance acts as an isolated data silo.
Balancing capacity across these isolated silos requires moving files manually, updating client network mappings, and scheduling extensive maintenance windows. If one controller becomes overwhelmed by heavy input/output (I/O) requests, there is no native mechanism to offload that traffic to a less utilized system. This rigid structure ultimately restricts business agility and significantly inflates total cost of ownership through continuous administrative intervention.
Engineering the Scale Out NAS Architecture
A scale out nas functions fundamentally differently from legacy storage. Instead of deploying isolated appliances, it aggregates independent storage nodes into a single, unified cluster operating under a global namespace. Administrators can seamlessly expand both capacity and performance simultaneously simply by adding new nodes to the existing cluster.
To ensure that data and network traffic do not bottleneck on a single node, the scale out nas must employ highly efficient algorithmic data placement. The most effective and mathematically robust method for achieving this is hash-based data distribution.
The Mechanics of Hash-Based Data Distribution
When a client writes a file to the cluster, the system does not arbitrarily look for the disk with the most free space. Instead, the scale out nas applies a cryptographic hash function—such as SHA-1 or a proprietary algorithm—to specific file attributes. These attributes typically include the file name, the inode number, or the logical block address.
This function generates a completely deterministic hash value. The storage cluster maintains a virtual hash space, often structured as a hash ring, that maps these numerical values to specific physical nodes and underlying disk drives. Because the mathematical algorithm strictly dictates data placement, the nas system naturally ensures a statistically even distribution of files across the entire hardware cluster. Every node actively participates in serving data, preventing the emergence of localized performance bottlenecks.
Eliminating Manual Rebalancing
The true operational advantage of this mathematical mechanism becomes apparent during cluster expansion. When administrators add a new storage node to a scale out nas, the cluster's hash ring automatically updates to accommodate the expanded hardware resources. The system recalculates the partition spaces, reassigning a proportional segment of the hash ring to the newly added node.
Consequently, the cluster initiates a background data transfer. It systematically moves only the specific subset of data that now maps to the new node, leaving the vast majority of the data untouched. This automated process happens entirely transparently. Administrators do not need to manually migrate volumes, reconfigure client mount points, or take production systems offline. The nas system continuously balances capacity and I/O load across all available hardware, preserving optimal performance parameters without requiring human intervention or complex migration scripts.
Integrating ISCSI NAS for Block-Level Workloads
While file-based protocols like NFS and SMB dominate standard unstructured data storage, many enterprise environments require block-level access to support relational databases and virtual machine hypervisors. Modern unified clusters accommodate this requirement by supporting an iscsi nas configuration. Implementing an iscsi nas protocol allows the storage cluster to serve block-level Logical Unit Numbers (LUNs) directly alongside standard file shares over the same Ethernet network.
The principles of hash-based distribution apply directly to block storage workloads as well. In an iscsi nas environment, the system applies the hashing algorithm to the logical block addresses rather than standard file metadata. This methodology slices the block data and distributes it evenly across the clustered nodes. It prevents heavily utilized LUNs from overwhelming individual controllers or specific disk groups. As a result, an iscsi nas deployment benefits from the exact same automated rebalancing, linear performance scaling, and hardware utilization efficiency as standard file-based NAS deployments.
System Resilience and Predictable Performance
Hash-based algorithms do significantly more than just balance disk capacity. They fundamentally improve the operational resilience of the nas system. By coupling hash distribution with advanced data protection protocols like erasure coding or network RAID, the storage cluster can survive multiple simultaneous hardware failures without data loss.
Rebuilding data after a drive or node failure operates on the exact same mathematical principles as cluster expansion. The surviving nodes reference the hash table to calculate the missing data segments and regenerate them automatically across the remaining healthy drives.
Furthermore, accessing data requires zero centralized metadata lookups. When a client requests a specific file or block, the system runs the hash function locally and instantly knows the precise node that holds the requested data. This mathematical predictability eliminates the latency associated with querying a central metadata server, ensuring predictable, rapid performance scaling as the scale out nas continues to grow.
Optimizing Your Enterprise Storage Strategy
Relying on manual data management and isolated storage silos is no longer a sustainable practice for modern data centers. The transition from legacy storage to a distributed scale out nas is a necessary architectural evolution for enterprises managing rapidly growing repositories of information.
By leveraging hash-based data distribution, organizations can scale their infrastructure seamlessly without incurring the severe operational penalties of manual rebalancing. Whether deploying standard file shares or a high-performance iscsi nas for virtualized environments, applying algorithmic data placement guarantees that your storage environment remains highly resilient, perfectly balanced, and prepared for future data demands. Review your current infrastructure bottlenecks and evaluate how automated data distribution can streamline your long-term storage operations.