Data centers constantly face the challenge of managing exponential data growth while maintaining strict uptime requirements. Expanding storage capacity or rebalancing data across existing nodes traditionally required scheduled maintenance windows, leading to application downtime and decreased productivity. Modern storage architectures have solved this problem by decoupling the logical data presentation from the physical storage hardware.
Understanding how a system handles capacity expansion and load balancing is critical for storage administrators. A primary mechanism for achieving seamless expansion is through advanced distributed file systems. These systems allow administrators to add new nodes to a cluster dynamically. Once a node joins the cluster, the system must redistribute data to optimize capacity utilization and performance across all available resources.
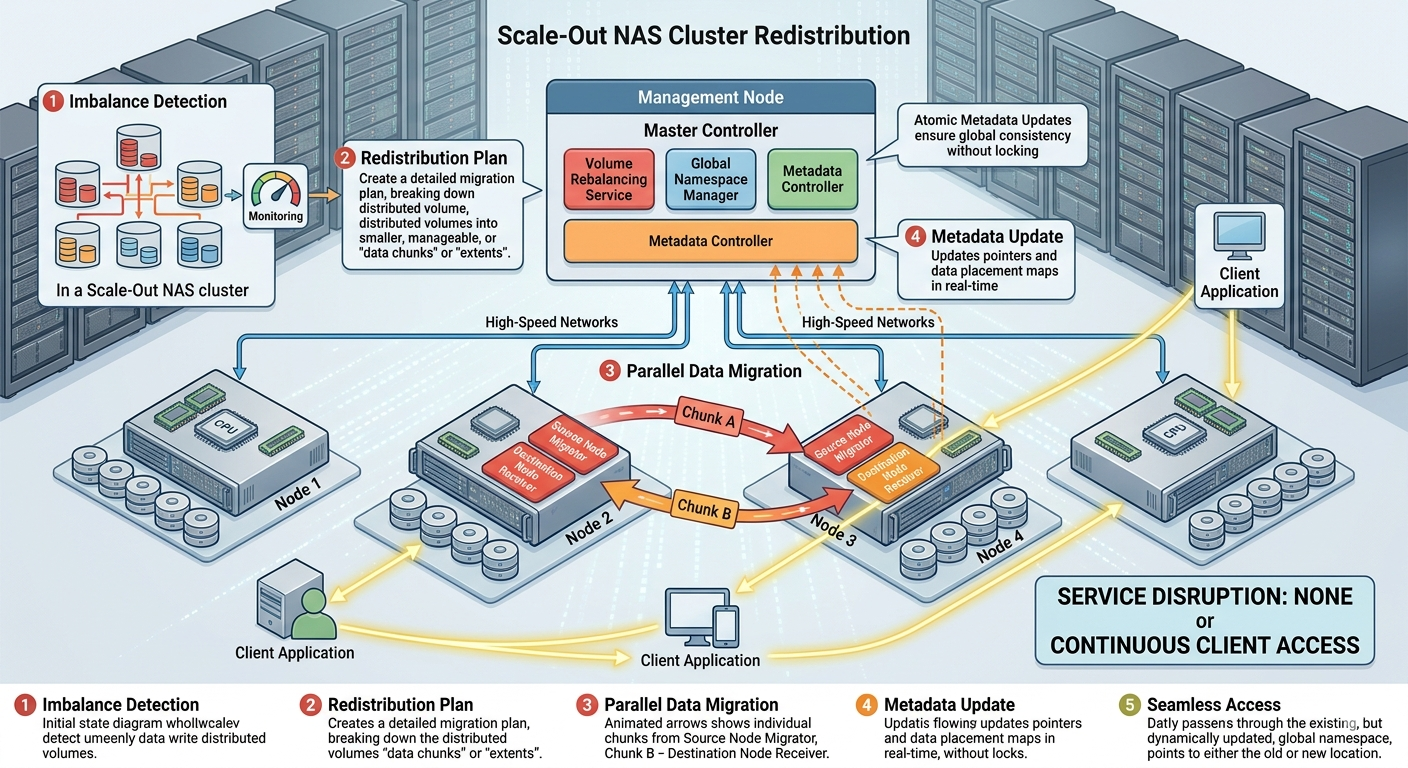
This post explains the technical mechanisms that allow Scale out nas Storage to process distributed volume redistribution without service disruption. We will examine the underlying architecture, data rebalancing algorithms, and security measures that ensure data remains available and intact during background operations.
Understanding Distributed Architecture in Scale Out NAS Storage
Traditional storage arrays typically rely on a dual-controller architecture, which creates physical limitations on capacity and performance. When those limits are reached, administrators must initiate a complex hardware migration.Scale out nas Storage resolves this bottleneck by utilizing a clustered architecture. Multiple independent nodes operate together to present a single, unified namespace to clients.
The Role of Network Attached Storage
At its core, Network Attached storage provides file-level data access to a variety of client applications over standard Ethernet protocols like NFS and SMB. In a scale-out model, the Network Attached storage cluster distributes both data and metadata across all participating nodes. This distribution ensures that no single node becomes a performance chokepoint.
When an organization adds a new node to the Network Attached storage cluster, the total available capacity and aggregate throughput increase immediately. However, the existing data resides entirely on the older nodes. The cluster must perform distributed volume redistribution to move a portion of the existing data to the new node. This background process equalizes capacity and prevents the older nodes from carrying a disproportionate amount of the I/O load.
The Mechanics of Zero-Downtime Volume Redistribution
Executing distributed volume redistribution without disrupting client I/O requires sophisticated software engineering. The Scale out nas Storage operating system must manage read and write requests simultaneously with background data movement.
Data Rebalancing Algorithms
The redistribution process relies on intelligent rebalancing algorithms. When a new node is initialized, the Scale out nas Storage system scans the file system's metadata to identify which data blocks or files should migrate. The algorithm calculates the optimal data layout based on capacity thresholds and performance metrics.
Instead of moving large volumes of data at once, the system transfers data in small, manageable chunks. This granular approach prevents the redistribution process from monopolizing the cluster's CPU and network resources. Storage administrators can usually configure the priority of the redistribution task, ensuring that front-end client operations always receive preferential treatment over background data movement.
Client I/O Redirection
A critical component of non-disruptive redistribution is transparent I/O redirection. If a client attempts to read or write a file while it is being moved, the Network Attached storage system must ensure data consistency.
When a file migration begins, the system locks the specific blocks being moved for a fraction of a second. If a write request arrives for a block currently in transit, the system queues the request or redirects it to the new destination node once the transfer completes. The cluster's metadata map updates atomically. Clients connected to the Network Attached storage cluster experience a slight latency bump, but they do not lose their connection or receive an I/O error. The file system protocol handles the retry logic gracefully.
Ensuring Data Integrity During Redistribution
Data movement inherently introduces risk. Hardware failures, network partitions, or unexpected power losses during redistribution could potentially corrupt data if proper safeguards are missing. Scale out nas Storage systems employ several layers of protection to guarantee data integrity during these background operations.
Leveraging Immutable Snapshots for NAS
One of the most effective data protection strategies is the use of Immutable Snapshots for NAS. A snapshot captures a point-in-time, read-only copy of the file system. Before a major volume redistribution event, the system can automatically generate a snapshot.
Immutable Snapshots for NAS provide a crucial fail-safe. Because these snapshots cannot be altered or deleted by malicious actors or rogue processes, they guarantee that a pristine copy of the data exists. If an unforeseen catastrophic failure occurs during data migration, administrators can mount the Immutable Snapshots for NAS to recover the exact state of the file system prior to the event.
Furthermore, Immutable Snapshots for NAS operate using redirect-on-write technology. This means they consume minimal storage capacity and have no negative impact on the performance of the Scale out nas Storage cluster. The redistribution engine simply ignores the snapshot blocks, focusing only on moving the active file system data to the new nodes.
High Availability and Fault Tolerance Mechanisms
Beyond Immutable Snapshots for NAS, distributed storage systems utilize erasure coding or strict data mirroring. When data moves to a new node during redistribution, the system simultaneously updates the erasure coding parity blocks.
If a drive or an entire node fails while the volume redistribution is processing, the Scale out nas Storage cluster detects the failure immediately. The system halts the specific migration thread associated with the failed component and uses the parity data to rebuild the missing information on the surviving nodes. The Network Attached storage architecture guarantees that the single namespace remains online and accessible throughout the entire hardware failure and subsequent rebuild process.
Sustaining Enterprise Workloads with Modern Storage
Managing data at a petabyte scale requires infrastructure that adapts seamlessly to changing demands. Scale out nas Storage provides the architectural foundation necessary to expand capacity and optimize performance dynamically. By leveraging intelligent rebalancing algorithms, transparent I/O redirection, and robust security measures like Immutable Snapshots for NAS, organizations can achieve distributed volume redistribution without ever taking their critical applications offline.
Storage administrators should continuously evaluate their storage infrastructure to ensure it meets these high-availability standards. Upgrading to advanced clustered systems minimizes operational risk and eliminates the costly downtime associated with legacy hardware migrations.