As data environments grow in complexity and sheer volume, system architects require storage architectures that can dynamically expand without disrupting client access. Scale out nas Storage has emerged as the definitive architecture for these massive datasets. Unlike legacy systems that rely on a single, monolithic controller, this modern approach distributes data and metadata across a cluster of independent nodes. This distributed nature allows organizations to add capacity and compute power on the fly.
However, expanding a cluster introduces a critical technical challenge: node redistribution. When a system administrator adds a new node to the cluster, the system must redistribute existing data to balance the load and optimize capacity. During this rebalancing process, files physically move from one node to another. Maintaining client access to these files while they migrate requires sophisticated engineering.
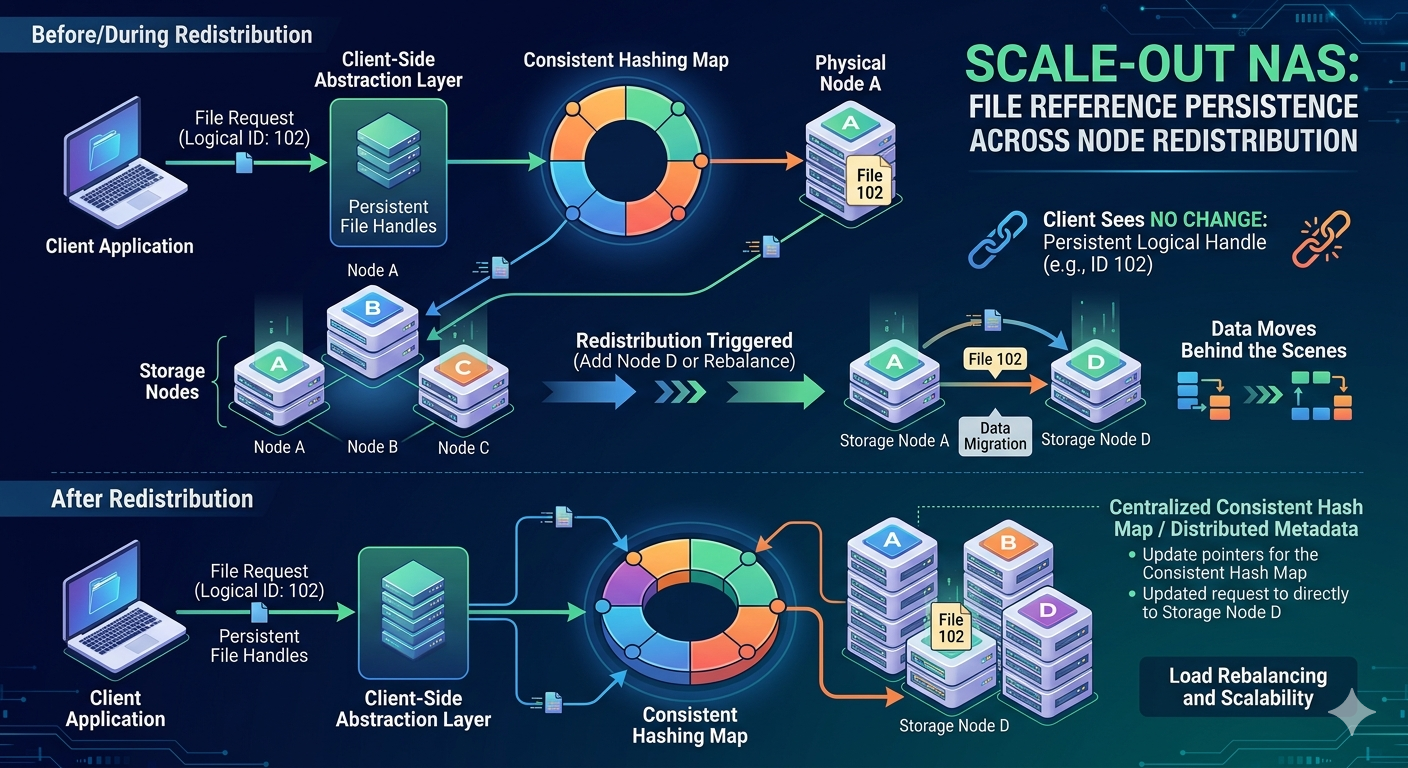
If a client holds a reference to a file, that reference must remain valid even if the file's physical location within the cluster changes. This concept is known as file reference persistence. Understanding how a storage cluster manages this persistence is essential for storage engineers tasked with maintaining high availability. This article explains the underlying mechanisms that allow continuous file access during node redistribution.
The Architecture of Network Attached storage Clusters
To understand file reference persistence, we must first examine how a distributed cluster manages data. Traditional Network Attached storage systems utilize a tightly coupled architecture where a single file system maps directly to specific physical disks. In a distributed model, the file system is abstracted away from the physical hardware.
Distributed Metadata Management
In a scale out nas Storage cluster, metadata—the data about the data—is usually decoupled from the file content itself. Metadata includes file names, permissions, timestamps, and crucially, the physical location of the data blocks. Depending on the specific vendor implementation, this metadata might be managed by dedicated metadata servers or distributed symmetrically across all nodes in the cluster.
By distributing the metadata, the cluster ensures that no single node becomes a bottleneck. When a client requests a file, the system queries the metadata layer to locate the specific node holding the required data blocks. This abstraction layer is the foundation of file reference persistence.
Node Redistribution and Data Rebalancing
Node redistribution occurs whenever the physical topology of the cluster changes. The most common trigger is adding a new node to increase capacity or performance. Conversely, removing a node for maintenance or decommissioning also forces a redistribution.
When a new node joins the cluster, it begins completely empty. To prevent the older nodes from remaining at full capacity while the new node sits idle, the cluster initiates a background rebalancing operation. The cluster calculates an optimal data distribution map and begins migrating blocks of data and their associated metadata to the new node.
During this migration, the system must guarantee that applications relying on this Network Attached storage experience zero downtime. The file system must seamlessly track the file's old location, its new location, and its transient state while in motion.
Mechanisms of File Reference Persistence
Maintaining a persistent file handle across these physical migrations relies on a combination of consistent hashing, virtual IP routing, and dynamic metadata updates.
Virtual File Handles
When a client mounts a Network Attached storage volume and opens a file, it does not receive a physical disk address. Instead, the client receives a virtual file handle. This handle is a logical pointer. The storage cluster maintains an internal mapping table that translates this virtual handle to a physical location.
Because the client relies solely on the virtual handle, the backend cluster can move the physical data blocks without the client ever knowing. The cluster simply updates its internal mapping table.
Consistent Hashing Algorithms
Many scale out nas Storage implementations use consistent hashing to determine data placement. In a consistent hash ring, both the nodes and the file IDs are hashed into the same mathematical space. A file is assigned to the node that is closest to it on the hash ring.
When a new node is added to the hash ring, only a fraction of the total data needs to be reassigned. The consistent hashing algorithm recalculates the placement map. If a file is scheduled for migration, the cluster creates a temporary forwarder.
Forwarding Pointers and Lock Management
While a file is physically moving, the cluster utilizes forwarding pointers. If a client attempts to read or write to a file that is currently migrating, the original node receives the request. The original node checks its updated metadata, sees that the file is moving, and uses the forwarding pointer to redirect the client's request to the new node.
Simultaneously, the cluster must manage distributed file locks. If an application holds a write lock on a file, that lock state must transfer to the new node along with the data. Distributed lock managers track these states, ensuring that data corruption does not occur during the redistribution process.
Client-Side Implications and Network Routing
The storage cluster's internal mechanisms are only half of the equation. The network layer must also route client traffic correctly. Network Attached storage protocols like NFS (Network File System) and SMB (Server Message Block) handle network disruptions differently.
Dynamic IP Allocation
To ensure high availability, scale out nas Storage clusters utilize dynamic IP allocation. Each node hosts one or more virtual IP addresses. If a node goes offline, its virtual IP address instantly fails over to a surviving node in the cluster.
During a planned node redistribution, virtual IP addresses might be rebalanced alongside the storage capacity. If a client's connection is momentarily dropped because an IP address moved to a different node, modern NFS and SMB clients are designed to automatically reconnect. Upon reconnection, the client presents its virtual file handle. Because the metadata layer is fully synchronized, the receiving node recognizes the handle, locates the data (even if it recently moved), and resumes the operation without application failure.
Ensuring Seamless Operations During Expansion
System administrators rely on scale out nas Storage to provide infinite capacity expansion without maintenance windows. File reference persistence is the critical engineering achievement that makes this possible. By abstracting the physical location of data through virtual file handles, utilizing consistent hashing for minimal data disruption, and implementing intelligent forwarding pointers, these systems ensure high availability.
As enterprise data continues to grow, understanding the mechanics of your Network Attached storage cluster allows you to scale your infrastructure confidently. Through careful metadata management and dynamic network routing, storage architectures can seamlessly adapt to physical changes, keeping critical applications running without interruption.