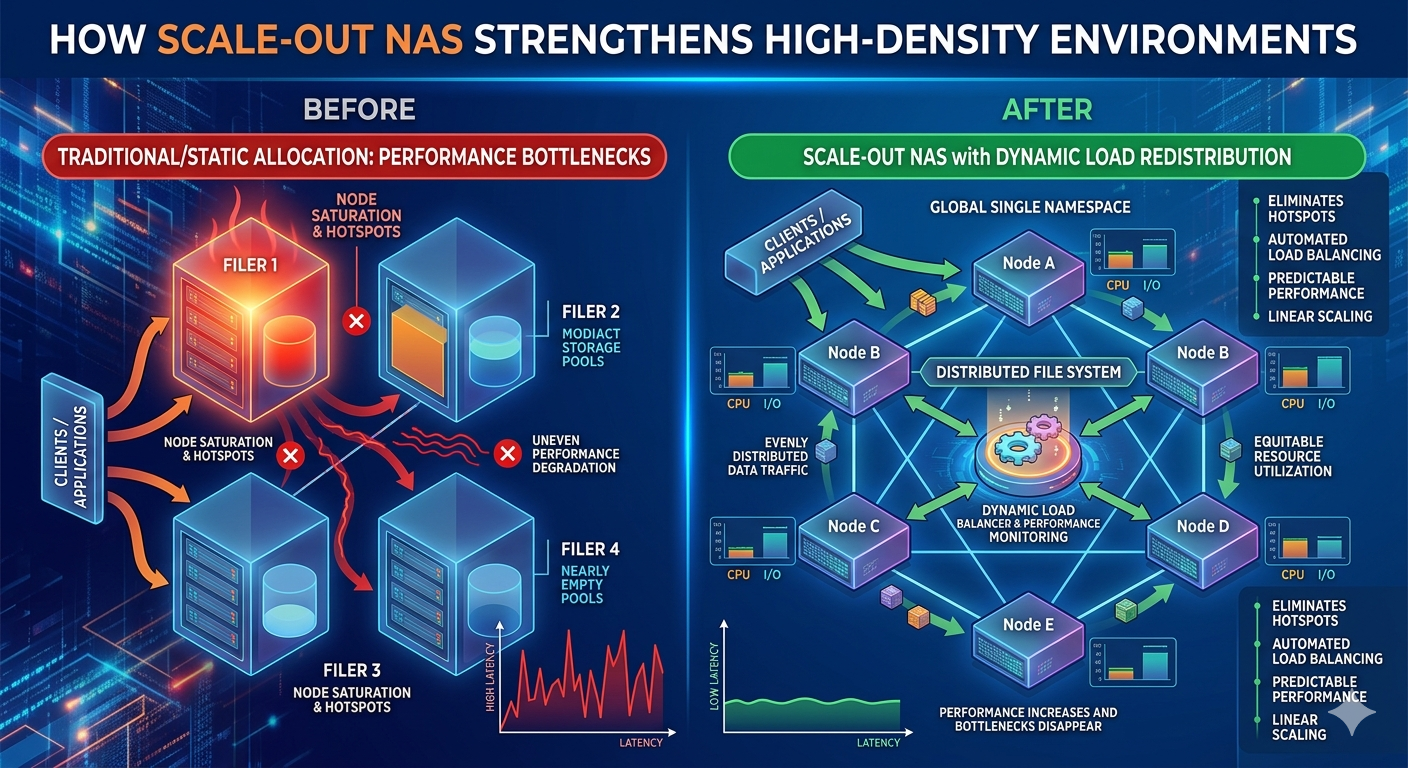
Managing high-density data environments requires infrastructure capable of processing millions of concurrent input and output operations. Enterprise architectures frequently encounter severe performance degradation when relying on legacy scale-up storage models. These older frameworks channel traffic through a single pair of controllers. As data volumes expand and client requests multiply, these controllers inevitably become restrictive chokepoints. This limitation increases latency, disrupts critical business applications, and restricts overall operational efficiency.
Resolving these architectural flaws demands a transition toward distributed file systems. Implementing Scale out nas Storage provides the structural foundation necessary for continuous data availability and consistent throughput. Instead of simply adding isolated disk shelves to an existing and overburdened controller head, system administrators can integrate independent storage nodes into a unified, single-namespace cluster. Each added node contributes simultaneous increases in storage capacity, CPU processing power, and network bandwidth.
Within these advanced Network Storage Solutions, dynamic node-level load redistribution serves as the primary mechanism for maintaining optimal performance. By actively balancing client requests and data placement across the entire cluster, the system prevents any single hardware component from becoming overwhelmed. The following sections examine the technical mechanics behind this intelligent load balancing and how it systematically eliminates processing bottlenecks in high-demand environments.
The Architecture of Distributed File Systems
Legacy storage networks operate on a monolithic framework. When a specific dataset becomes highly active, the dual-controller setup forces all associated traffic through a narrow processing corridor. This results in heavy queuing and delayed read/write responses.
Scale out nas Storage redesigns this data path entirely. The architecture distributes the file system across a cluster of interconnected nodes. Every node acts as an active participant in handling client requests. When a client application queries a file via protocols like NFS or SMB, the request does not have to route through a centralized master node. Instead, the cluster utilizes intelligent routing protocols to direct the request to the most appropriate node available.
This decentralized approach means that performance scales linearly. Adding ten nodes to a cluster multiplies the available processing power and memory cache by ten. This linear scalability is a defining characteristic of modern Network Storage Solutions, ensuring that infrastructure can grow symmetrically with data demands.
Eliminating the Single Point of Failure
Beyond performance limitations, legacy systems present a localized point of hardware failure. If a primary controller experiences a fault, the system must execute a complex failover to a secondary controller, often causing temporary service interruptions. Scale out nas Storage mitigates this risk through erasure coding and data mirroring across multiple distinct nodes. If one node fails, the cluster seamlessly redirects client traffic to surviving nodes holding the redundant data, maintaining continuous operations without noticeable latency spikes.
Mechanisms of Node-Level Load Redistribution
The core advantage of these clustered environments lies in their ability to dynamically shift workloads. High-density data environments are characterized by unpredictable traffic spikes. A dataset that requires minimal access on Monday might become the target of massive computational analysis on Tuesday.
Continuous Traffic Monitoring and Analytics
To manage unpredictable workloads, Network Storage Solutions employ continuous telemetry gathering. The operating system running the cluster monitors CPU utilization, memory consumption, disk I/O, and network port bandwidth on every individual node in real time.
When a specific node begins approaching its maximum processing threshold, the system triggers a redistribution protocol. It identifies the client connections or specific data blocks causing the resource strain. Because the file system is distributed, the system can transparently migrate active client connections from the heavily loaded node to a node with excess capacity.
Automated Resource Allocation
This load balancing happens at multiple layers. At the network layer, DNS-based load balancing directs incoming connections to the least busy nodes. At the file system layer, dynamic redistribution ensures that the actual data blocks are evenly striped across the physical drives of the entire cluster.
If an administrator adds a new node to a functioning Scale out nas Storage cluster, the system automatically detects the new hardware. The cluster then initiates a background process to migrate a portion of the existing data onto the new node. This auto-balancing feature ensures that the new node immediately begins sharing the computational and storage burden, rather than sitting idle while older nodes struggle with capacity limits.
Addressing High-Density Data Challenges
High-density environments, such as those utilized in machine learning, genomic sequencing, and high-performance computing, generate massive amounts of unstructured data. Processing this data requires high throughput for large file reads and low latency for small file transactions.
Throughput and Latency Optimization
Dynamic node redistribution directly addresses both throughput and latency. By preventing any single node from queuing too many requests, the system keeps latency consistently low. Furthermore, because data is striped across multiple nodes, a single large file read can pull data simultaneously from several nodes at once. This parallel processing aggregates the bandwidth of multiple network connections, delivering throughput speeds that far exceed the physical limitations of a single storage controller.
Modern Network Storage Solutions often incorporate intelligent caching algorithms alongside load redistribution. Frequently accessed data is promoted to high-speed NVMe or SSD tiers within the optimal nodes, while cold data automatically migrates to denser, cost-effective spinning disks. This automated tiering works in tandem with node balancing to ensure that high-priority workloads always have access to the fastest available hardware resources.
Designing Resilient Infrastructure
Data generation will continue to accelerate, forcing enterprises to reevaluate their infrastructure limitations. Clinging to legacy, scale-up architectures guarantees future bottlenecks, increased management complexity, and escalating costs. Transitioning to clustered architectures is no longer optional for organizations managing petabytes of unstructured data.
To maintain operational efficiency, IT leaders must prioritize systems that offer autonomous resource management. Implementing Scale out nas Storage provides the necessary framework to handle unpredictable workload spikes without manual intervention. By leveraging dynamic node-level load redistribution, enterprise architectures can achieve the sustained performance, high availability, and seamless scalability required to support modern, data-intensive applications. Evaluating and deploying these advanced Network Storage Solutions ensures that your infrastructure remains a robust foundation for ongoing technical innovation.