Structural data reorganization is a critical operational procedure for organizations handling massive volumes of data. As file systems grow, administrators must optimize storage arrays, rebalance workloads, and migrate data to new hardware or cloud environments. During these transitions, maintaining continuous retrieval consistency is a significant technical challenge. Users and applications must be able to read and write data without encountering lock errors, corrupted files, or stale information.
When data structures are actively moving, the underlying storage architecture must resolve file requests dynamically. If a user queries a file that is mid-transfer between storage tiers or physical drives, the system needs a mechanism to serve the correct data blocks seamlessly. This prevents application downtime and ensures data integrity. Network-Attached Storage systems handle this process through sophisticated abstraction layers and real-time metadata updates.
Understanding how NAS Storage handles these transitions requires an examination of file-level protocols, namespace virtualization, and synchronization techniques. For large-scale operations, Enterprise nas solutions provide advanced features to keep operations running smoothly. Furthermore, hybrid deployments often integrate these local architectures with cloud infrastructure, such as Azure disk storage, to balance performance and capacity.
By examining the internal mechanisms of these storage solutions, IT professionals can better plan their data migrations and structural reorganizations with zero impact on user productivity.
The Challenge of Structural Data Reorganization
Data reorganization involves altering the physical or logical placement of data within a storage system. This might include volume expansion, defragmentation, tiering hot data to fast flash drives, or archiving cold data to slower spinning disks.
During these operations, file pointers shift. The primary challenge is ensuring that incoming read and write requests are accurately routed to the correct physical blocks. If an application attempts to write to a file while its underlying blocks are being moved, data corruption can occur. Similarly, read requests might return incomplete data if the system fails to track the file's state accurately.
Core Mechanisms of NAS Storage
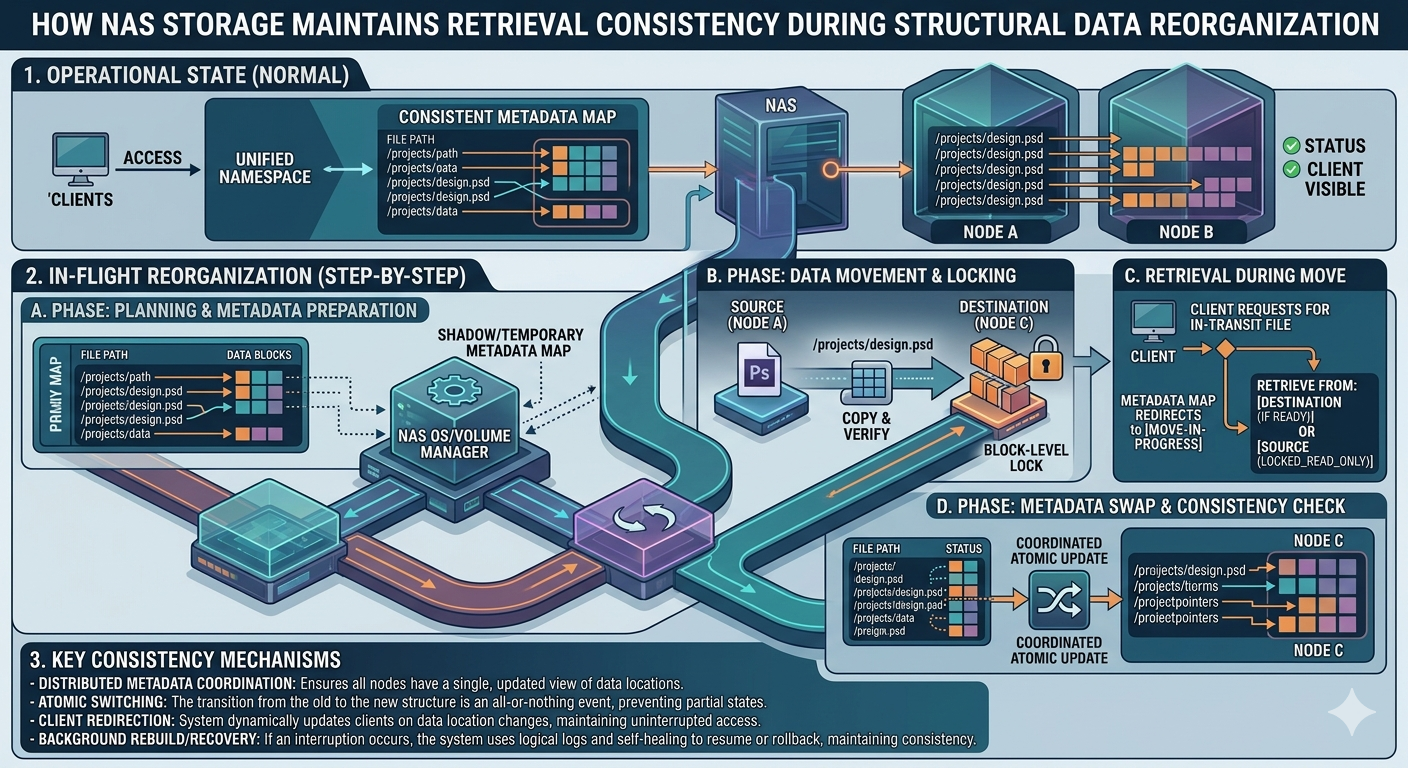
To solve these synchronization problems, NAS Storage relies on a decoupled architecture where the logical file system is separated from the physical storage blocks. This abstraction allows the system to move blocks physically while maintaining a consistent logical path for the end-user.
Metadata Management and Namespace Abstraction
The foundation of retrieval consistency lies in metadata management. A NAS Storage system uses a global namespace. This namespace acts as a virtual directory, hiding the physical location of the data from the client. When a reorganization event triggers a data move, the system copies the data to the new location in the background.
Once the data transfer is complete, the system performs an atomic update to the metadata. This means the pointer switches from the old physical location to the new one instantaneously. Because the update is atomic, there is no fractional state where the file is unreadable. Clients querying the file system continue using the same logical path, completely unaware that the underlying physical blocks have changed.
File-Level Locking Protocols
When data is actively being modified by a user during a reorganization event, NAS Storage systems utilize strict file-level locking protocols, typically managed through NFS (Network File System) or SMB (Server Message Block).
If a file is locked for a write operation, the storage system will temporarily pause the background migration of that specific file. It waits for the client to release the lock, ensuring that the migration process only captures the most recent, fully committed version of the file. This guarantees that no active edits are lost during structural shifts.
Scaling Operations with Enterprise NAS
Standard storage systems work well for small offices, but massive data centers require more robust capabilities. An Enterprise nas system incorporates distributed file systems across clustered nodes. This clustered approach provides high availability and fault tolerance.
During a structural reorganization, an Enterprise nas distributes the migration workload across multiple controllers. If one node becomes overloaded or fails, another node seamlessly takes over the migration and client requests. This load balancing ensures that retrieval consistency is maintained even under heavy transactional pressure.
Furthermore, an Enterprise nas often employs redirect-on-write (ROW) snapshot technology. Before moving data, the system takes a snapshot. If an application requests data that is currently in transit, the system can serve the read request directly from the snapshot. This ensures consistent read performance and data integrity while the primary blocks are being relocated.
Hybrid Integrations and Azure Disk Storage
Modern infrastructure rarely relies on a single hardware solution. Many organizations extend their local file systems into the cloud to achieve better scalability. Integrating local systems with Azure disk storage requires robust caching and synchronization mechanisms to maintain consistency over wide area networks.
When reorganizing data to include cloud tiers, the local system acts as a caching gateway. Frequently accessed files remain on local flash arrays, while cold data is seamlessly migrated to Azure disk storage. If a user requests a file that has been moved to Azure disk storage, the local system intercepts the request.
The system then retrieves the necessary blocks from the cloud, caching them locally before serving them to the user. To maintain consistency, the integration relies on asynchronous replication and write-back caching. When a user modifies a file that resides primarily in Azure disk storage, the local system acknowledges the write immediately to the user, and then synchronizes the changes to the cloud in the background. This architecture ensures that users experience local-like performance and strict consistency, even when the data physically resides in the cloud.
Frequently Asked Questions
How does atomic metadata updating work?
Atomic updates ensure that a change to the file system's index happens instantly. The file pointer changes from the old location to the new location in a single, indivisible operation. This prevents clients from encountering a "file not found" error during the exact millisecond the data physically moves.
Can users edit files during data reorganization?
Yes. Systems utilize locking mechanisms and write-back caching. If a file is being actively edited, the system will temporarily halt the migration of that specific file or capture the changes dynamically, ensuring no data is lost or corrupted.
Why use cloud block storage for file data?
By mounting Azure disk storage to a local file gateway, organizations can achieve virtually limitless capacity. The local appliance translates the block-level cloud storage into standard file protocols (NFS/SMB), providing a consistent user experience while reducing on-premises hardware costs.
What differentiates high-end solutions from standard storage?
An Enterprise nas provides active-active clustering, meaning multiple controllers process data simultaneously. This prevents bottlenecks during massive structural reorganizations and provides uninterrupted access even if hardware components fail.
Strategic Next Steps for Storage Management
Maintaining continuous access to data during structural reorganization is essential for business continuity. The abstraction of logical paths from physical blocks, combined with atomic metadata updates and strict file locking, allows NAS Storage systems to shift terabytes of data without interrupting application workflows.
As your organization scales, upgrading to an Enterprise nas can provide the clustered performance necessary for large-scale migrations. Furthermore, evaluating hybrid architectures that incorporate Azure disk storage can provide elastic capacity while maintaining strict retrieval consistency. Assess your current file system's metadata handling capabilities to ensure your infrastructure can support seamless data reorganization without compromising operational integrity.