High-performance computing environments generate and process massive volumes of data at unprecedented speeds. Within these demanding infrastructures, data reuse patterns emerge as a critical variable affecting overall system throughput. When multiple compute nodes repeatedly request the same datasets, the underlying storage architecture must deliver high input/output operations per second (IOPS) and low latency. Failing to optimize for these reuse patterns results in severe bottlenecks, stalling processing pipelines and underutilizing expensive computational resources.
To address these challenges, engineers must architect storage solutions that intelligently manage data locality and caching. Traditional storage arrays often struggle to keep pace with the concurrent read requests typical in machine learning, genomic sequencing, and financial modeling. Therefore, optimizing a network-attached storage infrastructure becomes a fundamental requirement for maintaining computational efficiency.
By strategically designing the storage ecosystem, organizations can ensure that frequently accessed data remains readily available to compute clusters. This requires a systematic approach to hardware selection, file system configuration, and data protection mechanisms.
Understanding Data Reuse Patterns in Complex Workloads
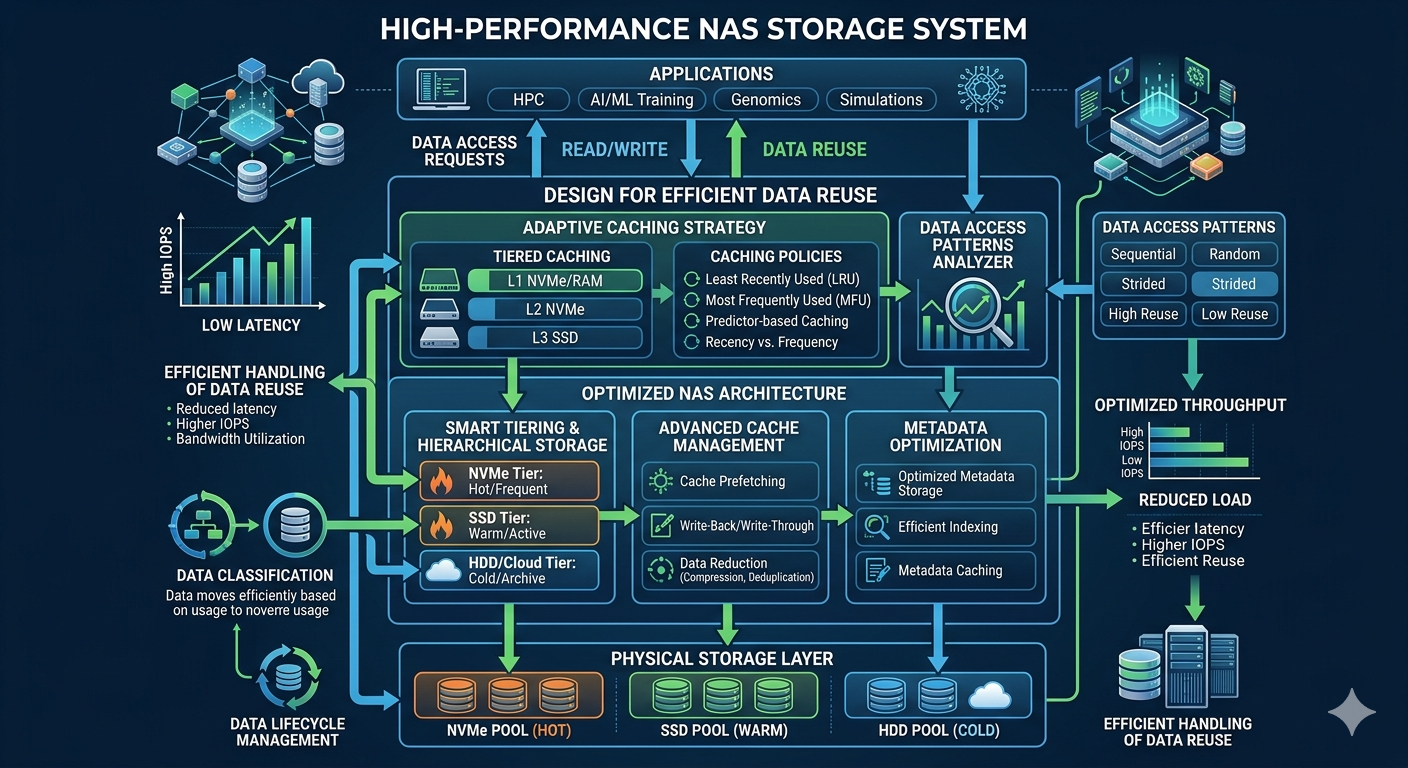
Data reuse occurs when specific files or blocks are accessed multiple times by one or more applications during a computation cycle. In high-performance applications, these patterns typically manifest as read-heavy workloads where the initial data ingestion is followed by intense, concurrent read operations. Recognizing the specific access frequency and data size is the first step in designing an effective storage architecture.
Compute nodes accessing the same reference databases or training sets create localized hotspots. If the NAS Storage is not configured to handle these sudden spikes in concurrent reads, the entire network experiences increased latency. Engineers must analyze I/O profiles to determine whether the reuse is temporal (accessed repeatedly over a short period) or spatial (sequential blocks accessed together). This analysis dictates the caching algorithms and tiering policies required to maintain optimal performance.
Architecting the Ideal NAS Appliance for Data Proximity
Selecting the right hardware foundation is critical for managing data reuse. A modern NAS Appliance must provide scalable throughput and robust caching capabilities. Flash-based storage media, specifically NVMe solid-state drives, deliver the low latency required for high-frequency data access. However, deploying an all-NVMe infrastructure for petabyte-scale environments is often cost-prohibitive.
To balance performance and cost, storage architects implement tiered storage models within the NAS Appliance. Hot data—files currently experiencing high reuse—resides on the NVMe tier. As the data cools and access frequency declines, automated tiering software moves the files to lower-cost SAS or SATA drives. This ensures that the NAS Appliance dedicates its fastest resources exclusively to the data actively driving computational workloads.
Advanced Caching Mechanisms
Beyond physical storage tiers, RAM-based caching plays a pivotal role in accelerating data delivery. When a compute node requests a file, the NAS Storage system loads it into system memory. Subsequent requests for the same file are served directly from RAM, bypassing the physical drives entirely. For high-performance applications, maximizing the memory capacity of the NAS Appliance significantly reduces response times for highly reused datasets.
Overcoming Network and Protocol Bottlenecks
Even the fastest storage media cannot overcome a congested network or inefficient file sharing protocols. High-performance environments require high-bandwidth, low-latency network interconnects such as 100GbE or InfiniBand. Furthermore, the choice of protocol directly impacts how efficiently the NAS Storage handles concurrent requests.
NFS (Network File System) and SMB (Server Message Block) are the standard protocols used in NAS Storage environments. For high-performance computing, advanced protocol versions like NFSv4.1 with parallel NFS (pNFS) allow compute nodes to access storage devices directly and in parallel. This eliminates the traditional single-node bottleneck, distributing the I/O load across multiple storage nodes and drastically improving read performance for reused data.
Implementing a Resilient NAS Backup Strategy
While optimizing for performance is the primary objective, safeguarding the data remains a non-negotiable requirement. High-performance applications often process mission-critical data that cannot be easily recreated. Therefore, an integrated NAS Backup architecture must operate seamlessly without degrading the performance of the primary computational workloads.
Traditional backup methods, which walk the file system to identify changed data, create massive I/O overhead. In environments with billions of files, this approach cripples the NAS Storage system. Instead, storage administrators must utilize storage-level snapshots and block-level incremental replication. These technologies capture point-in-time copies of the data instantly, creating a reliable NAS Backup with minimal impact on production performance.
Furthermore, replicating these snapshots to a secondary, lower-cost NAS Appliance or cloud storage tier ensures off-site disaster recovery capability. A well-designed NAS Backup protocol ensures that data integrity is maintained, and recovery time objectives (RTO) are met, even in the event of catastrophic hardware failure. It is essential to schedule these replication tasks during periods of lower computational demand to preserve bandwidth for primary data reuse tasks.
Frequently Asked Questions
How does data tiering improve read performance?
Data tiering automatically moves frequently accessed files to the fastest storage media, such as NVMe drives, while shifting colder data to high-capacity HDDs. This ensures that concurrent read requests for reused data are served with minimal latency, maximizing overall system throughput.
Why is pNFS recommended for high-performance workloads?
Parallel NFS (pNFS) separates the control path from the data path. This allows compute clients to communicate directly with multiple storage nodes simultaneously. By distributing the read and write operations, pNFS prevents any single storage controller from becoming a bottleneck during intense data reuse cycles.
What is the most efficient way to perform a NAS Backup in environments with millions of files?
The most efficient method is utilizing block-level storage snapshots combined with asynchronous replication. This approach bypasses traditional file-system walking, instantly securing the data state and transferring only the changed blocks to the secondary NAS Backup target, thereby preserving primary system performance.
Future-Proofing High-Performance Data Infrastructures
Optimizing storage for data reuse is an ongoing engineering challenge. As computational models grow in complexity, the demands placed on storage architectures will continue to escalate. By implementing intelligent caching, strategic data tiering, and parallel network protocols, organizations can build a storage ecosystem capable of sustaining maximum computational efficiency.
Careful hardware selection combined with a robust, zero-impact data protection strategy ensures that the infrastructure remains both fast and resilient. Engineers must continuously monitor I/O profiles and adjust tiering policies to align with evolving workload characteristics, guaranteeing that the storage environment accelerates, rather than hinders, organizational objectives.