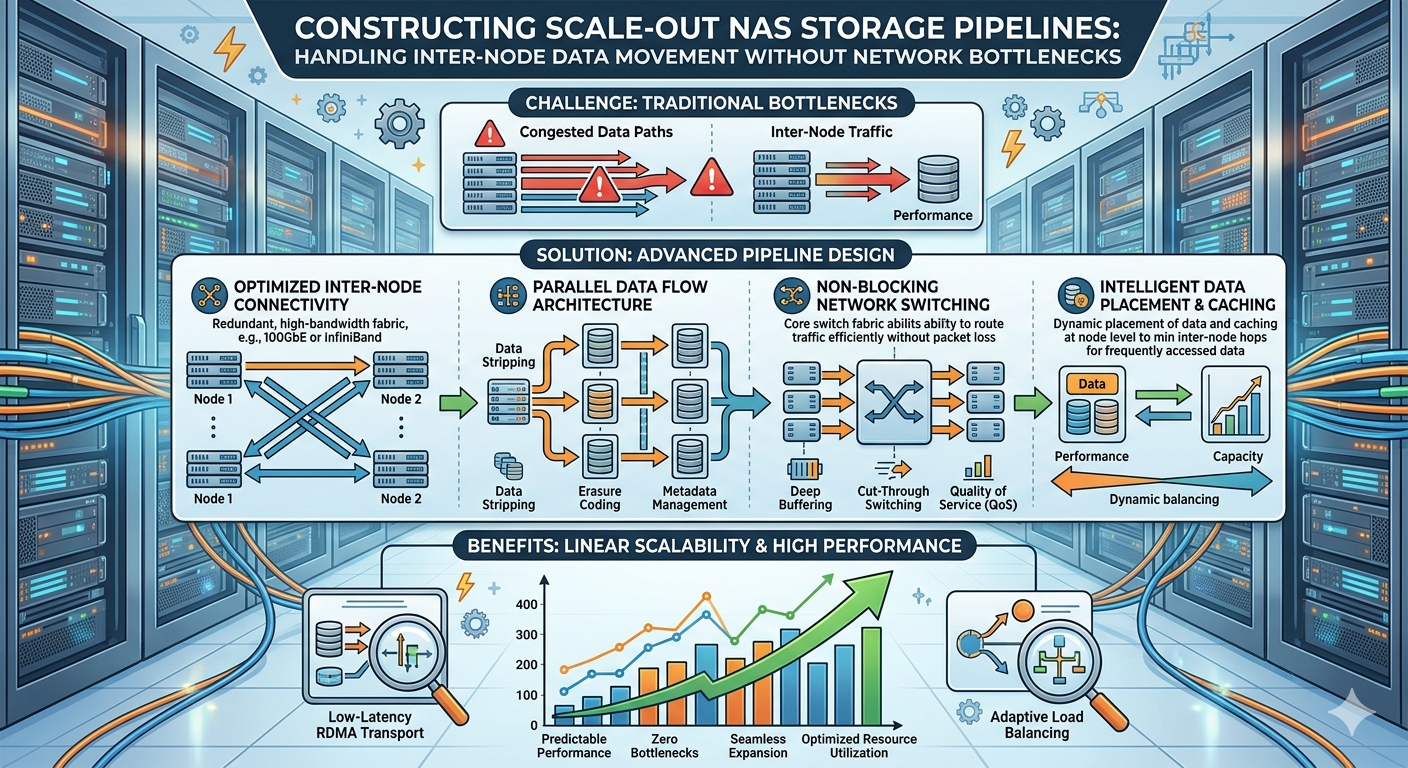
Data growth requires infrastructure capable of scaling performance and capacity simultaneously. Constructing pipelines capable of handling inter-node data movement without network bottlenecks is a primary engineering challenge for modern data centers. When expanding capacity by adding nodes, the internal communication overhead between these nodes can saturate network links, leading to degraded application performance and unacceptable latency.
System administrators and storage architects must design infrastructures that seamlessly distribute data across multiple physical devices. By optimizing hardware topologies, implementing advanced networking protocols, and tuning software-defined data pipelines, organizations can ensure high availability and consistent throughput. This article details the technical methodologies required to build highly resilient pipelines, ensuring efficient inter-node data movement across distributed environments.
The Mechanics of Scale out nas Storage
Traditional storage arrays face hard limits regarding processing power and bandwidth. Scale out nas Storage addresses this limitation by distributing the workload across a cluster of independent nodes. Each node contributes CPU, memory, and disk resources, creating a unified pool of storage. As the cluster grows, capacity and aggregate performance increase linearly.
Understanding Inter-Node Traffic
The fundamental challenge in distributed architectures is managing the "east-west" traffic. This refers to the data moving laterally between nodes within the data center. When a client requests a file, the node receiving the request might not hold the actual data. The cluster must retrieve the data blocks from the corresponding peer nodes, assemble the file, and deliver it to the client. If the network fabric connecting these nodes lacks sufficient bandwidth or utilizes inefficient routing protocols, this internal traffic creates severe congestion.
Designing a robust pipeline requires separating client-facing "north-south" traffic from internal inter-node traffic. Best practices dictate provisioning dedicated network interfaces and physical switches specifically for cluster communication. This physical separation prevents intensive client workloads from interfering with critical background tasks, such as data replication, rebalancing, and node synchronization.
Optimizing Network Attached storage Pipelines
The foundation of any high-performance cluster lies in the physical and logical configuration of the underlying network. Network Attached storage protocols have evolved significantly, moving beyond traditional TCP/IP limitations to embrace low-latency, high-throughput alternatives.
Implementing RDMA for Low-Latency Transfers
Remote Direct Memory Access (RDMA) is critical for modern scale-out systems. RDMA allows a node to write data directly to the memory space of another node, completely bypassing the operating system kernel. This bypass eliminates the CPU overhead associated with context switching and buffer copying in traditional TCP/IP stacks.
Protocols such as RDMA over Converged Ethernet (RoCE) and InfiniBand provide the microsecond latency required for synchronous data replication across a Scale out nas Storage cluster. Implementing RoCE requires a lossless Ethernet fabric, achieved by configuring Priority-based Flow Control (PFC) and Explicit Congestion Notification (ECN) on the data center switches. These protocols instruct the network to pause specific traffic classes before buffers overflow, preventing packet loss and ensuring predictable inter-node data transfer rates.
Designing the Physical Switch Fabric
Legacy hierarchical network topologies, featuring access, aggregation, and core layers, introduce variable latency depending on the physical location of the nodes. To eliminate these network bottlenecks, engineers must deploy a spine-leaf architecture.
In a spine-leaf topology, every leaf switch connects to every spine switch. This design ensures that any node connected to any leaf is exactly one hop away from any other node in the cluster. This consistent, predictable latency is paramount for Network Attached storage arrays functioning as a single, cohesive file system. Furthermore, utilizing high-bandwidth uplinks (such as 100GbE or 400GbE) between the leaf and spine layers guarantees sufficient capacity to handle aggressive data rebalancing operations when new nodes are added to the environment.
Software-Defined Traffic Management
Hardware optimization must be paired with intelligent software routing to maximize pipeline efficiency. Scale out nas Storage software includes sophisticated algorithms designed to monitor network health, distribute workloads, and reroute traffic dynamically during hardware failures.
Load Balancing and Path Multipathing
Advanced storage operating systems distribute incoming client connections uniformly across all available nodes using SmartConnect or similar DNS-based load balancing mechanisms. Once a connection is established, the software determines the optimal path for inter-node communication.
Multipathing technologies allow nodes to utilize multiple physical network links simultaneously. By aggregating bandwidth across multiple ports, the system can achieve higher aggregate throughput while providing active-active redundancy. If a switch port or cable fails, the storage software transparently shifts the traffic to the surviving links without interrupting client operations.
Data Locality and Caching Algorithms
To further minimize inter-node network utilization, engineers configure advanced data locality algorithms. The software attempts to process data on the node where it physically resides, rather than pulling it across the network. Additionally, aggressive use of Non-Volatile Memory Express (NVMe) solid-state drives for read and write caching absorbs bursty workloads. By satisfying requests directly from high-speed cache memory, the system reduces the necessity for backend inter-node disk access, preserving valuable network bandwidth for critical synchronization tasks.
Frequently Asked Questions
What defines a Scale out nas Storage cluster?
A distributed system where multiple independent nodes operate together to present a single file system namespace to clients. Unlike scale-up architectures, expanding this system involves adding entire nodes containing CPU, memory, and disks, allowing performance and capacity to grow in tandem.
How does Network Attached storage differ from a SAN?
A Storage Area Network (SAN) provides block-level access to data, typically over Fibre Channel or iSCSI, requiring the client to manage the file system. In contrast, this file-based system manages the file system internally, allowing clients to access data using standard protocols like NFS and SMB.
Why is inter-node traffic problematic?
As clusters grow, the internal communication required for data replication, metadata synchronization, and stripe management increases exponentially. Without dedicated network infrastructure, this lateral traffic competes with client requests, leading to severe latency spikes and network saturation.
Can RDMA be deployed on standard Ethernet switches?
Yes, using RoCEv2. However, the Ethernet switches must support Data Center Bridging (DCB) features, specifically PFC and ECN, to provide the lossless network environment that RDMA operations require to function reliably.
Future-Proofing Your Storage Architecture
Designing pipelines to support massive data sets requires rigorous attention to both hardware topologies and software configurations. Network bottlenecks within distributed systems are rarely caused by a single failure point; they are the result of compounding inefficiencies across the data path. By separating client and cluster traffic, implementing a spine-leaf switch fabric, and leveraging low-latency protocols like RDMA, engineers can build highly resilient environments.
As data generation continues to accelerate, the principles of efficient inter-node communication will remain the bedrock of reliable infrastructure. Organizations must continually audit their physical network topologies and tune their logical traffic management policies to ensure their Scale out nas Storage pipelines remain highly available, scalable, and capable of handling future computational demands. Evaluate your current deployment against these engineering standards to guarantee your Network Attached storage environment delivers uncompromising performance as your capacity requirements scale.