Managing exponential data growth requires strategic infrastructure decisions. As organizations accumulate massive volumes of unstructured data, IT departments face a significant challenge: balancing performance requirements with storage costs. Storing all data on high-performance media is financially unsustainable, while relying solely on high-capacity, lower-performing drives creates unacceptable bottlenecks for critical applications.
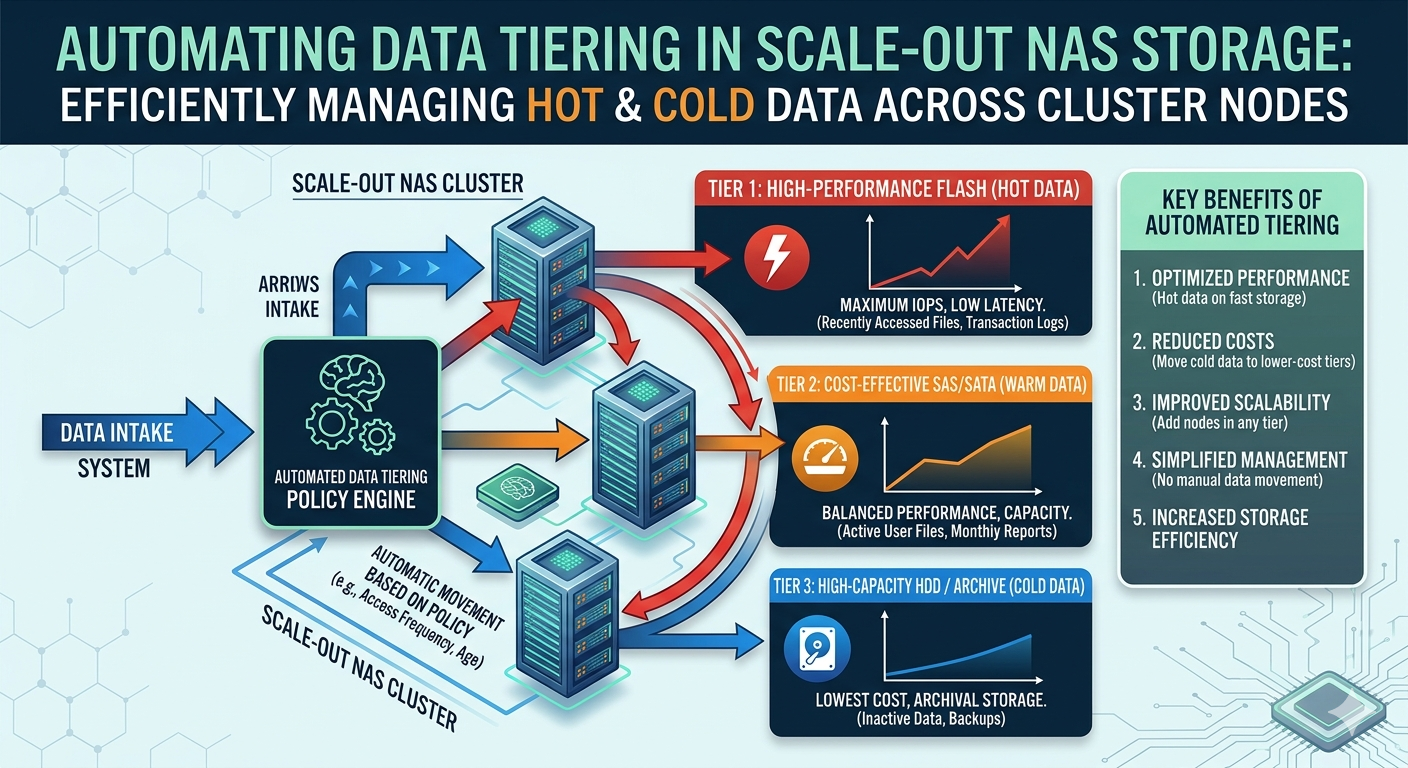
The solution lies in automating data tiering within scale-out NAS storage environments. This methodology systematically categorizes and moves data based on access frequency, ensuring that infrastructure resources are allocated efficiently. By dynamically shifting files between high-speed solid-state drives (SSDs) and cost-effective hard disk drives (HDDs) or cloud repositories, enterprises achieve optimal performance without overspending on hardware.
This article details the mechanics of automated data tiering in Network Attached storage architectures. You will learn how to distinguish between hot and cold data, understand how data tiering operates across cluster nodes, and discover the specific operational benefits of implementing an automated tiering strategy in your data center.
Understanding Hot and Cold Data in Network Attached Storage
Effective data management begins with data classification. In any Network Attached storage environment, data typically falls into distinct temperature categories based on its access frequency and relevance to immediate computing tasks.
Defining Hot Data
Hot data refers to mission-critical files that users and applications access frequently. This includes active databases, virtual machine files, and ongoing media production assets. Because immediate retrieval and low latency are essential for business operations, hot data must reside on the fastest available storage media, such as NVMe or enterprise-grade SSDs.
Defining Cold Data
Conversely, cold data encompasses files that are rarely accessed. Examples include historical logs, compliance archives, completed project files, and backup images. Storing cold data on premium solid-state media wastes valuable resources. Instead, this data is better suited for high-capacity, lower-cost storage tiers, such as spinning disks (HDDs) or offsite cloud storage.
The Mechanics of Scale-Out NAS Storage
To understand automated tiering, one must first understand the underlying architecture of scale-out NAS storage. Traditional scale-up storage relies on a single dual-controller system; when capacity is reached, the entire system must be replaced or expanded with expansion shelves that share the same limited controller bandwidth.
Scale-out NAS storage operates differently. It utilizes a distributed file system that spans multiple independent nodes, which are clustered together to form a single, unified storage pool. When an organization needs more capacity or performance, administrators simply add another node to the cluster. The system automatically redistributes the data and the computational load across the expanded environment.
This clustered architecture provides the perfect foundation for automated tiering. Nodes can be populated with different types of storage media. Performance nodes handle the intense input/output operations per second (IOPS) required for hot data, while capacity nodes provide deep storage for cold data.
How Automated Data Tiering Works Across Cluster Nodes?
Automated data tiering software continuously monitors data access patterns across the entire storage cluster. Instead of requiring system administrators to manually identify and migrate aging files, the system relies on predefined policies and machine learning algorithms to execute these movements in the background.
Metadata Scanning and Policy Execution
The tiering engine scans file metadata—such as creation date, last modified date, and last accessed date. Administrators configure specific policies, setting parameters such as "move any file not accessed in 60 days to the capacity tier." When a file meets these criteria, the software orchestrates a block-level or file-level transfer from the high-performance node to the high-capacity node.
Seamless Data Migration
Crucially, this automated migration is entirely transparent to the end-user and the application. The scale-out NAS system maintains the original file path and directory structure. When a user requests a cold file that has been tiered to a capacity node, the system retrieves it automatically. If the file is modified and becomes active again, the tiering engine promotes it back to the hot tier to ensure optimal performance for subsequent accesses.
Key Benefits of Automated Tiering
Implementing automated tiering within a scale-out architecture delivers several measurable advantages to enterprise IT operations.
Capital Expenditure Reduction
By migrating inactive data to lower-cost nodes, organizations significantly reduce their reliance on expensive SSDs. This extends the lifespan of the primary storage investment. Companies only need to purchase premium flash storage for the small percentage of data that actually requires high IOPS, drastically lowering overall capital expenditures.
Optimized System Performance
Removing cold data from the performance nodes frees up processing power, cache, and bandwidth. The SSDs operate more efficiently when they are not saturated with dormant files. Consequently, the applications that depend on hot data experience lower latency and faster throughput.
Reduced Administrative Overhead
Manual data migration is tedious, prone to human error, and completely unscalable in petabyte-scale environments. Automating this process liberates storage administrators from constantly monitoring capacity alerts and writing custom migration scripts. IT teams can redirect their focus toward strategic infrastructure planning and security enhancements.
Best Practices for Implementation
To maximize the value of automated data tiering, organizations must deploy the technology strategically.
Define Granular Tiering Policies
Broad, sweeping policies can lead to unintended performance degradation if active data is prematurely demoted. Analyze application workloads and user behavior to establish granular policies. Different departments may require different retention periods on the performance tier.
Utilize Analytics and Monitoring
Leverage the reporting tools integrated into your Network Attached storage platform. Monitor the volume of data moving between tiers to ensure your policies are effective. If the system is constantly promoting data back to the hot tier (a phenomenon known as thrashing), the demotion policies are likely too aggressive and need adjustment.
Plan for Network Bandwidth
Data migration between cluster nodes consumes internal network bandwidth. Schedule aggressive tiering operations or deep metadata scans during off-peak hours to ensure they do not interfere with frontend user performance and application latency.
Maximizing Storage Efficiency Through Automation
Data volume will continue to expand, but storage budgets rarely scale at the same rate. Automating data tiering in scale-out NAS storage provides a systematic, intelligent method for bridging this gap. By continuously aligning data value with storage cost, organizations achieve a highly efficient, self-optimizing infrastructure.
To advance your storage strategy, begin by auditing your current data footprint to determine the exact ratio of hot to cold data in your environment. Evaluate your existing Network Attached storage capabilities to confirm whether they support granular, automated tiering. Finally, initiate a small-scale proof of concept with non-critical workloads to validate the performance and cost benefits before executing a global rollout.